Do you know the difference between scalability and performance? Which one do you need? Whether you are building, buying or selling web-based software, this post will teach you what you need to know in order to make the right choice.
I touched the surface of this topic in one of my previous posts, Scalable, Flexible and Cheap, Pick 2 you can’t have All 3, when discussing how to understand customer requirements regarding scalability. I learned that when a customer orders a software project from you and says “It must scale”, it can basically mean anything.
A few questions should help understand whether the customer means scalability from a technical- or business point of view. Business scalability means whether the business model can be scaled for a bigger audience. This is a bigger concept, covering market, process, localization and various other properties, including the technical scalability. Engineers often forget that scalability is not always only technical. However, in this post I will only discuss the technical one.
Having narrowed down to technical scalability, there is still room for misunderstanding. The customer may actually mean performance. If you are the subcontractor, you need to ask the right questions to figure this out. If you happen to be sitting on the other side of the table and you are outsourcing the software development to some other company, it is very good to know the difference too. There are plenty of subcontractors out there who just implement whatever was originally requested.
In various discussions, I hear all the time people say “this does not scale” when something is not as fast as expected or “Wow, this is really scalable” when something is fast. This is another reason for writing this post. Scalability and performance are not synonyms.
A high performance website is what one could call a “fast” website. Sometimes this is all you need. You might know in advance how many users are going to use it but require that the page responds quickly. This is usually achieved by code optimizations, bundling/packing/minifying resources and doing various other configurations.
A high scalability website is a website, which performance-level can be maintained by adding more capacity when the load increases. Some websites need to scale for growing traffic, others for growing amount of data. Many need to scale for both. A website can be slow and perform badly even if it scales well.
Regarding scalability, there are two types of scalability: vertical and horizontal. Vertical scalability means that capacity is increased by upgrading the server(s) to more powerful ones. Horizontal scalability means that capacity is increased by adding more servers of the same kind to the system. Horizontal scalability is preferred, since costs will often grow somewhat linearly to capacity. When scaling vertically, costs will often grow exponentially to capacity, since hardware gets very expensive at the high-end.
In practice, many systems only scale horizontally to a certain point. This is usually because they consist of many components, of which some cannot be scaled horizontally. When these components become bottlenecks, they need to be scaled vertically, resulting in a non-linear cost structure.
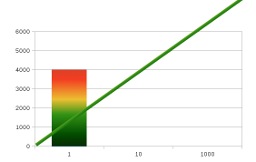
As earlier said, a website can perform badly even if it scales well. For example a website having a response time of 2 seconds could be considered slow and performing badly. If this website can handle 1000 users with one server, 10000 with 10 servers and 100000 with 100 servers, still maintaining its performance level (2s response time), it would be considered a highly scalable website.
Scalability and performance can have dependencies, both with positive and negative impact on each other. Consider a website, which architecture is changed into a more scalable Service Oriented Architecture (SOA), resulting in many more layers and web services. Requests may have to pass several layers causing a performance drop. On the other hand, some performance optimization tricks (or hacks) may be hard to scale. However, performance optimizations will often save resources, which will let you handle much more traffic with the same servers; hence, you will not reach your bottlenecks as early.
So, back to the question, which one do you need?
If you expect traffic or amount of data to grow, you need an architecture that can be scaled to meet the future needs by investing in proportion to the need. Hence, you need a horizontally scalable website.
If you know the traffic and amount of data is going to be within some reasonable known boundaries, but expect the website to be fast, you need a high performance website, designed for the specified amount of load.
Whichever you go for, remember that premature optimization is the root of all evil.