Do you want to build a web app? You probably want it to scale, since it will become the next facebook and needs to be able to handle millions of simultaneous users. But you need flexibility in the architecture, since you may want to do bigger changes or pivot easily when needed. Naturally, you have a very low budget and the software needs to be built quickly. Sounds familiar, doesn’t it? These 3 things are important; however, you cannot get them all at once. The real question to ask yourself is which ones do you need at the moment?
All too often non-technical people put too much weight on scalability at a too early stage. When working as a consultant I discussed many projects with different startups wanting to outsource the development of their software. Many of them asked me for an offer of a web based app containing lots of different features. Sometimes there was a requirement that the app must scale to millions of simultaneous users or something similar to that. Everything was planned with a “Build it and they will come” mentality, which is very rare to work on the web. The problem was that most of these startups did not fully understand what scalability meant. People think of scalability in 3 different ways:
- That the software is built in such a way that costs grow linearly when traffic grows or amount of data grows; meaning that scaling up happens by just adding more servers. This is referred to as horizontal scalability.
- That the website can handle heavy traffic without any actions. This means that option 1) is done and there are lots of servers in place already.
- The website is fast and responds quickly. I like to call this a high performance website, which I see as a different thing than a high scalability website.
Unfortunately most people want type 2 scalability. Usually after learning about server costs and what needs to be done in practice, they want type 1 instead. But depending on the complexity of the app, type 1 may also require a significant amount of work in order to scale horizontally above a certain threshold.
A common misconception is that scalability is always good to have in place. The truth is that premature optimization in terms of scalability is very bad. Scalability often results in loss of flexibility. I define flexibility as the possibility to easily make modifications to the software or pivot quickly. This is a very important tradeoff that one needs to understand; therefore, I am going to explain what needs to be done from an implementation point of view to achieve these properties in web software. Jump directly to “What should you focus on”-subsection if you feel it gets too technical.
Flexibility
To have a fully flexible system, you may want to go with a relational database and a fully normalized schema. This makes sure there are no inconsistencies in the data whatever you do; Thus, it should be quite easy to implement any new functionality with various ad hoc queries to the database. You probably want to let the database take care of as much as possible. Preferably you want to run everything on one server, but having a separate database server and a few identical web servers behind a load balancer should not harm the flexibility.
Scalability
Depending on your application, your first step to a more scalable architecture may be caching. You want to minimize the load of the database, so you cache data that is used often. If you need to show fresh data to your users, you need to delete the affected cache entries when data changes. As you see, developers need to take this into account and they can no longer just do ad hoc queries to the database.
Additionally, you may need to take in new technologies, like a search engine. Whenever data changes in your database, you need to update the data in the search index and other potential storages to avoid inconsistencies. New features may also require schema changes, which may need to be taken into account in all different systems. You have lost a lot of flexibility.
Furthermore, to be able to scale for really big datasets, you cannot just do complex database queries. You need the data to already be in the format you are going to use it. This requires denormalization, which means that you have a lot of redundant data. An example of denormalization could be a photosharing website keeping a separate count for the number of comments an image has, in order to be able to easily sort images by number of comments. Without this number, the database would have to count the comments each time. The more the database is denormalized, the harder it is to do quick changes. You may also want to switch to a NoSQL database if you plan to denormalize a lot.
Finally, scalable apps usually use plenty of application specific tricks. These tricks may not work if there are bigger changes to the application logic. This means that when functionality changes, the developer needs to come up with a new way to scale; thereby spending a lot more time implementing the change.
Flexibility and scalability together
Sometimes you need both flexibility and scalability. In this case you have to define within what scope you need to be flexible. Full flexibility is not going to be possible. However, by planning how to migrate data, re-calculate redundant data and using several other tricks, it should be possible to be flexible within the scope.
You may be able go into a Service Oriented Architecture (SOA) and build web services for retrieving any kind of data needed for features within the predefined scope. This way the scalability can be implemented in the web services (application servers) and developers can have quite good flexibility when developing on the web servers. The broader the scope is, the more expensive it is going to be.
What should you focus on?
Now we know that scalability will require certain design decisions that will make it harder to do changes in the future. If there is a need to be both scalable and flexible, you need to have a good understanding within what scope to be flexible. The cost wll be higher since the implementation is a lot harder. I think the best way to illustrate this equation of flexibility, scalability and cost is by using a ternary plot. Cost would refer to both time and money:
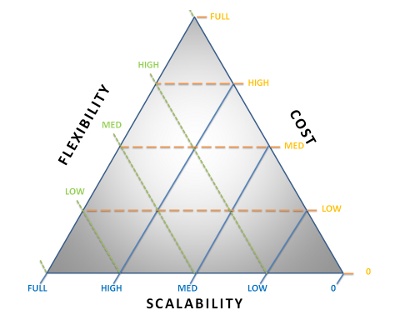
Now that you know the basics, the question is where do you want to be on the triangle? The wrong decision can be fatal for a startup, so understanding the pros and cons is important. I think it all comes down to what kind of a startup you are and at what stage you are.
Most new web apps built by various startups have enormous market risk, especially the ones trying out completely new concepts in new markets. Every startup has a runway of a certain length, during which it needs to find a profitable and scalable business model and fly or run out of cash and die. It needs to test and validate hypotheses as quickly as possible. This needs to be supported technically, therefore it is extremely important to be as flexible as possible in the beginning.
When product-market fit is reached, usage starts to grow rapidly. Now scalability becomes more and more important. It may be tempting to still keep things flexible and go for various other great ideas that come up here and there; however, this increases the cost and can be very dangerous for a startup which does not yet have all its processes in place. Therefore, the best approach is probably to productize what works and just scale up loosing as much flexibility as necessary. The fewer features got implemented during the flexibility stage, the easier it will be to scale. Due to this, it makes sense to keep the feature set as small as possible during the flexibility stage by removing unused or otherwise not working features.
There may of course come a day when there is a need for flexibility again, for example when the product is going to enter the mainstream market. The mainstream market usually requires a whole product, which naturally is going to require a lot of effort to build. But then again at this stage, the company has probably generated some revenue and raised more capital and the processes and technical competence are at a much higher level.
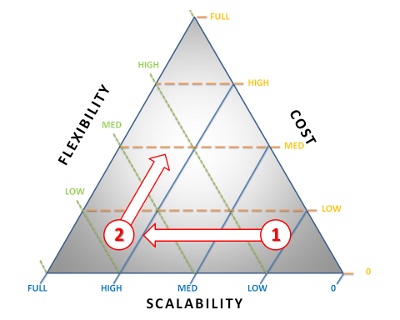
The point I am trying to make is that it is extremely important that everyone making product decisions understand what the cost of scalability is. It is so easy to fool yourself that whatever you are building is going to hit the jackpot and build too much scalability into the system. When you learn that it didn’t work, you are going to need to pivot. Either you pivot keeping the scalability but with high cost or you drop the scalability. Jumping back and forth in the triangle is going to be costly and is probably going to result in a lot of technical debt.
I would be very glad to hear what different successful and/or unsuccessful startups have done regarding flexibility and scalability at the early stages of a company. Any experiences?